1Learning Outcomes¶
Practice interpreting waveforms in timing diagrams.
Given an instruction, identify the critical path through the single-cycle datapath.
Approximate instruction timing based on the five phases of instruction execution.
🎥 Lecture Video
How should we time our single-cycle datapath? How should we set the clock frequency? In this section, we develop an approximation of instruction timing using the five steps to a RISC-V instruction.
2Timing Diagram for add¶
First, let’s consider the delays in our beloved add instruction. Review the add datapath in Figure 1.
Figure 1:The add datapath, updated from an earlier section’s simple add-only datapath. Use the menu bar to trace through the animation or access the original Google slides.
Figure 2 shows the waveforms for executing an add x1 x2 x3 instruction at address 0x100, followed by add x6 x7 x9 at address 0x104.

Figure 2:Timing diagram for add. Only relevant signal waveforms are shown.
3Critical path delay by instruction¶
Different instructions use different components of the datapath. We now update our definition of critical path to consider the path between clocked element inputs and outputs that matter for the given instruction. For example, accessing DMEM does not matter for an add, whereas setting up the RegFile data to write back does not matter for sw.
Table 1:Timing descriptions of components.
| Delay | Description |
|---|---|
| clk-to-q delay to transfer register input value to the output. | |
| Setup time to hold the register input stable before the rising clock edge. | |
| Propagation delay through a mux; assume the same delay for all muxes. | |
| Propagation delay through the simple adder that increments PC to the next instruction. | |
| Delay to read a register value from RegFile. | |
| Delay to read the instruction from IMEM. | |
| Delay to read a word from DMEM. | |
| Propagation delay through the ALU. | |
| Propagation delay through the immediate generator. | |
| Propagation delay through the branch comparator. |
Show Answer for add
addB. There are two “loops” that we consider:[3]
The PC update loop, measured from the PC output to the PC input:
The loop through the ALU, measured from the PC output to the RegFile input:
The critical path uses the longer loop through the ALU.
Figure 3:The beq datapath, updated from an earlier section’s simpler datapath. Use the menu bar to trace through the animation or access the original Google slides.
Show Answer for beq
beqE. Something else.
We leave this derivation to you. Note you may need to make new placeholder delays for control logic...!
Figure 4:The lw datapath, updated from an earlier section’s simpler datapath. Use the menu bar to trace through the animation or access the original Google slides.
Show Answer for lw
lwC. Load uses hardware in all five phases of the datapath. We still consider the two “loops” through the datapath[3]:
The PC update loop, still measured from the PC output to the PC input.
The much longer loop, measured from the PC output through the ALU and DMEM, to the RegFile input. We now consider additional hardware for loads:
Instruction Decode: The immediate generation block sets
immconcurrently with the RegFile retrieving the source register valueR[rs1]. We denote this delay as the larger of the two, .Execute: The ALU output computes the memory address, so we incur .
Memory: The DMEM read now matters, so we incur DMEM read time, .
4The single-cycle datapath clock is slow¶
To determine the clock frequency for the single-cycle datapath, we compute delays of each instruction’s critical path, then set the clock period as the worst-case delay incurred over all instructions.
To put some numbers to our earlier analysis, we will simplify our time estimates with Table 2, which assumes that the timing of each of the five steps to a RISC-V instruction are dominated by the major functional hardware units.
Table 2:Assume each of the five steps is dominated by a major hardware unit. Multiplexors, control unit, PC accesses, immediate generation, and branch prediction incur minimal delay.
| Step | Operation time | Major hardware unit |
|---|---|---|
Instruction Fetch (IF) | 200 ps | Read an instruction word from IMEM. |
Instruction Decode (ID) | 100 ps | Read register values from the RegFile. |
Execute (EX) | 200 ps | Perform arithmetic/logical operations in the ALU. |
Memory Access (MEM) | 200 ps | Read or write data from DMEM. |
Write Back (WB) | 100 ps | Write back to the RegFile. For single-cycle, we assume this is the delay of the WBSel mux and setup time. |
We can then produce the simplified timing diagram in Figure 5 for an instruction that uses all phases—like our lw instruction from earlier.
We can additionally construct
Table 3, which shows the time required for various instruction formats.
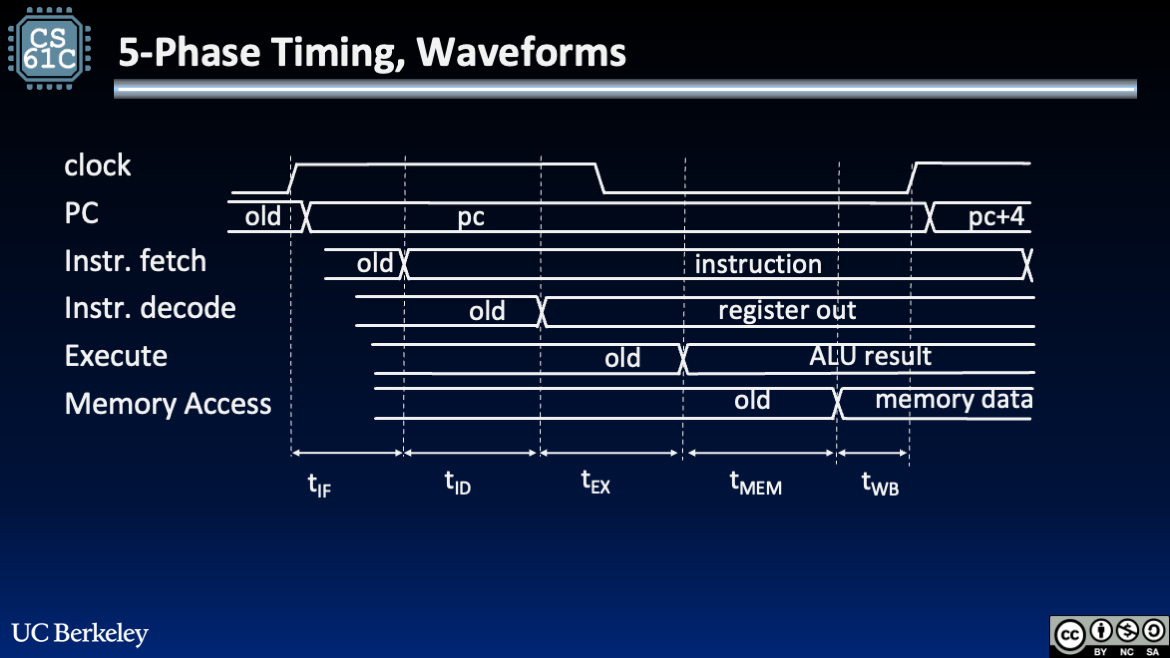
Figure 5:Approximate timing diagram for the five steps to a RISC-V instruction in the single-cycle-datapath.
Table 3:(P&H Figure 4.28). Total time for each instruction calculated from the simplified time for each phase.
| Instruction | IF (200ps) | ID (100ps) | EX (200ps) | MEM (200ps) | WB (100ps) | Total |
|---|---|---|---|---|---|---|
add | X | X | X | X | 600ps | |
beq | X | X | X | 500ps | ||
jal | X | X | X | 500ps | ||
lw | X | X | X | X | X | 800ps |
sw | X | X | X | X | 700ps |
While Table 3 above shows the shortest time to complete each instruction, we note that the single-cycle datapath, like all synchronous digital systems, shares a single clock.
We further note that each instruction’s critical path often involves accessing major hardware units in sequence. In other words, for most of each clock period, much of our hardware is idle and not computing additional data!
We address these performance issues and more in our pipelined datapath design up next. Stay tuned!
Note that the waveform represent bundles of wires with a hexadecimal value (contrast this with the clock’s binary high-low signal). The PC output
pcbundle of wires update at the same time, because flip-flops are wired in parallel. By contrast, thepc+4output does not stabilize simultaneously. Because the adder cascades single-bit adders in series, the least significant bits stabilize sooner than the more significant bits. In timing diagrams, we always show the transition to the correct value. Forpc+4, this occurs after the propagation delay of the most significant bit.There are two multiplexers controlled with ASel and BSel, respectively. Both propagation delays occur concurrently, so we only count for one mux’s propagation delay.